Welcome to another chapter in our exploration of natural language processing (NLP)! In our previous blog, we traced the journey from clunky Recurrent Neural Networks (RNNs) to the game-changing Transformer architecture introduced in the 2017 paper “Attention Is All You Need,” which paved the way for GPT. Today, we’re zooming in on a crucial yet underappreciated step in this pipeline: tokenization. Tokenization is the process that turns raw text into a format AI can understand, setting the stage for the Transformer’s magic and GPT’s conversational prowess. Whether you’re new to AI or a tech enthusiast, we’ll break it down with analogies, a clear example, and technical details to show how tokenization fuels modern NLP.
The Challenge: Making Sense of Raw Text
Before AI models like the Transformer or GPT can process text, they need to convert human language—messy, varied, and full of nuances—into a structured format. Raw text, like a sentence or a paragraph, is just a string of characters to a computer. For example, the sentence “The cat runs!” includes words, punctuation, and spaces, but a model doesn’t inherently understand these as meaningful units. Early NLP systems struggled with this, often relying on simplistic methods like splitting text by spaces, which couldn’t handle complex languages, slang, or special characters.
The Problem with Raw Text
Imagine trying to cook a recipe without measuring ingredients—you’d end up with a mess. Similarly, NLP models need a way to break text into consistent, meaningful pieces. Without this, they can’t learn patterns or generate coherent outputs. Early approaches faced challenges:
- Variable Word Forms: Words like “run,” “running,” and “ran” have similar meanings but different forms, confusing models.
- Punctuation and Special Characters: Symbols like “!” or contractions like “don’t” complicate text parsing.
- Language Diversity: Languages like Chinese don’t use spaces, and others have complex grammar, making simple splitting ineffective.
- Vocabulary Size: If every unique word is treated separately, the vocabulary becomes massive, slowing down training and requiring more memory.
Tokenization solves these issues by breaking text into smaller, manageable units called tokens, which the model can process efficiently.
Tokenization: The Foundation of NLP
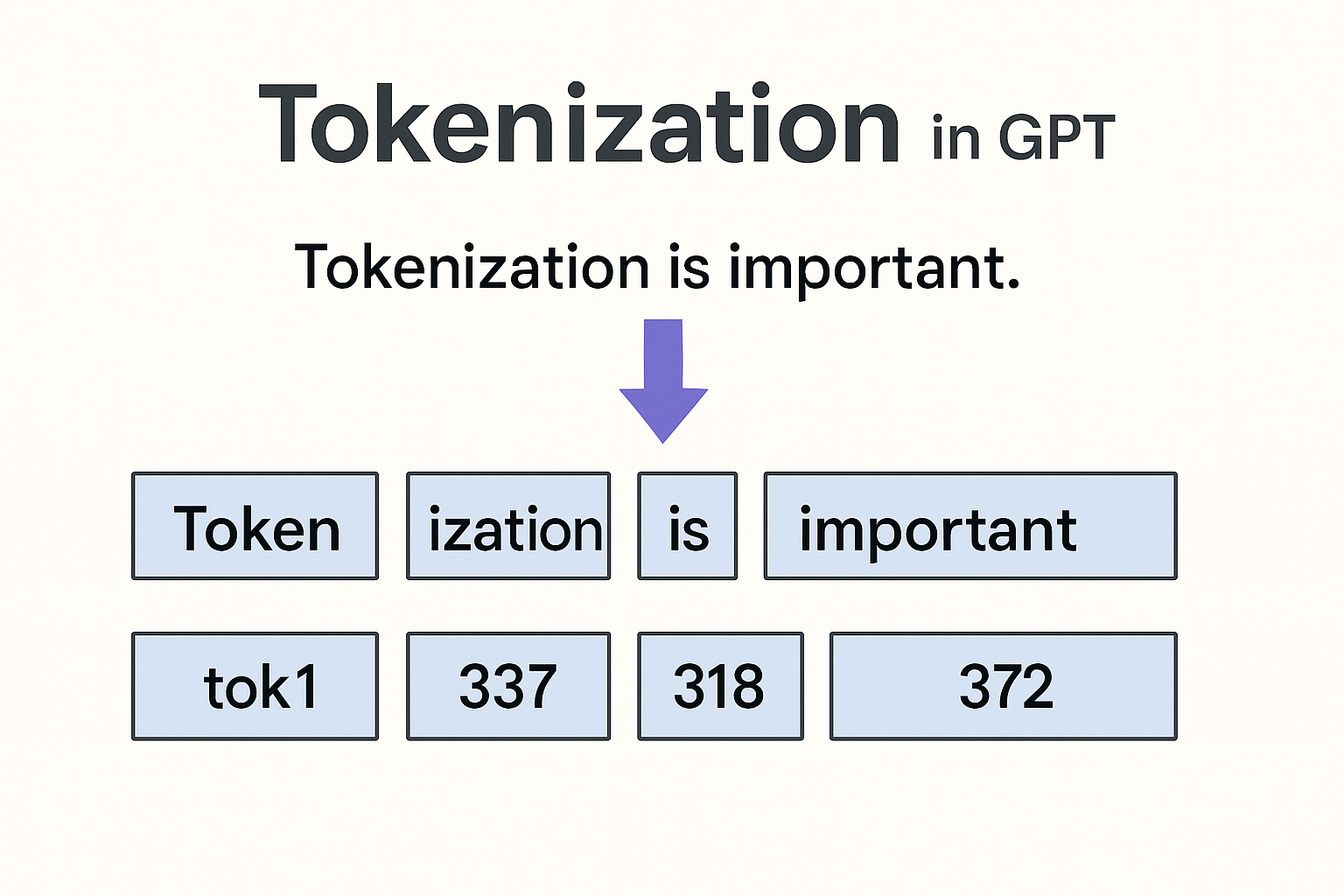
Tokenization is the process of splitting raw text into tokens—smaller units like words, subwords, or characters—that serve as the building blocks for NLP models. These tokens are then mapped to numerical representations (vectors) that models like the Transformer and GPT can understand. Think of tokenization as chopping ingredients into bite-sized pieces before cooking a dish: it makes the text digestible for AI.
Types of Tokenization
There are several approaches to tokenization, each balancing granularity and efficiency:
- Word-Based Tokenization: Splits text into words (e.g., “The cat runs!” → [“The”, “cat”, “runs”, “!”]). Simple but struggles with large vocabularies and rare words.
- Character-Based Tokenization: Treats each character as a token (e.g., [“T”, “h”, “e”, ” “, “c”, “a”, “t”, …]). Handles any text but results in long sequences, slowing processing.
- Subword Tokenization: Splits text into smaller units, like word pieces or morphemes (e.g., “running” → [“run”, “##ing”]). This balances vocabulary size and flexibility, and is widely used in modern models like GPT.
The “Attention Is All You Need” paper and GPT rely on subword tokenization (e.g., WordPiece or Byte-Pair Encoding), which we’ll explore in our follwoing example.
Analogy: Tokenization as a Recipe Prep
Imagine you’re a chef preparing a complex dish. Raw ingredients (text) like whole vegetables (sentences) need to be chopped into uniform pieces (tokens) before cooking (processing). Some ingredients are cut into big chunks (whole words), others into smaller bits (subwords), depending on the recipe. Tokenization ensures the model has the right “ingredients” to create a delicious output, like a coherent sentence or translation.
Tokenization in Action: Example with “The cat runs!”
Let’s see how tokenization works with the sentence “The cat runs!”, the same example we used in our Transformer blog. We’ll use Byte-Pair Encoding (BPE), a subword tokenization method popularized by models like GPT.
Step 1: Splitting into Tokens
BPE starts by breaking text into characters and iteratively merging frequent pairs to form subword units. For simplicity, assume a small vocabulary trained on a corpus where common words and endings are identified. For “The cat runs!”:
- Initial split: [“T”, “h”, “e”, ” “, “c”, “a”, “t”, ” “, “r”, “u”, “n”, “s”, “!”]
- After BPE merging (based on frequency in a corpus), it might become: [“The”, “cat”, “run”, “s”, “!”]
Here, “The,” “cat,” and “run” are common tokens, while “s” and “!” are separated to handle variations (e.g., “runs,” “running”) and punctuation.
Step 2: Mapping Tokens to IDs
Each token is assigned a unique ID from a vocabulary:
- Vocabulary: {“The”: 1, “cat”: 2, “run”: 3, “s”: 4, “!”: 5, …}
- Sentence tokens: [“The”, “cat”, “run”, “s”, “!”] → [1, 2, 3, 4, 5]
These IDs are the model’s “language”—numbers it can process.
Step 3: Vector Encoding
The token IDs are converted into vectors using an embedding layer:
- Each ID is mapped to a high-dimensional vector (e.g., 512 dimensions in the Transformer). For simplicity, assume 2D vectors:
- “The” (ID 1) → [1, 0]
- “Cat” (ID 2) → [0, 1]
- “Run” (ID 3) → [1, 1]
- “s” (ID 4) → [0, 0.5]
- “!” (ID 5) → [0.2, 0.2]
- Positional encodings are added to indicate token order (e.g., “The” is first, “cat” is second). The Transformer uses sine and cosine functions for this, but assume they’re baked into the vectors for simplicity.
These vectors ([1, 0], [0, 1], [1, 1], [0, 0.5], [0.2, 0.2]) are the input representations fed into the Transformer’s self-attention mechanism, as described in our previous blog.
Step 4: Self-Attention and Beyond
The Transformer processes these encoded vectors using scaled dot-product attention to create context-aware representations. For example, when focusing on “cat,” the model computes attention weights to weigh the importance of “The,” “run,” “s,” and “!,” producing a new vector that captures the sentence’s context (e.g., [0.599, 0.802] for “cat,” as shown previously). This process relies on tokenization to provide clean, consistent inputs.
Step 5: Decoding Back to Text
After processing, the Transformer’s decoder (or GPT’s decoder) generates output by converting context-aware vectors into token IDs via a linear layer and softmax. These IDs are mapped back to tokens (e.g., ID 3 → “run”) and reassembled into text. For example, generating “The cat runs!” involves decoding vectors into the sequence [1, 2, 3, 4, 5] → [“The”, “cat”, “run”, “s”, “!”].
The Journey to GPT: Tokenization’s Role
Tokenization was a critical enabler in the journey from RNNs to the Transformer and GPT. Here’s how it bridged the gap:
- Enabling Scalable Input Processing:
- RNNs used word-based tokenization, leading to massive vocabularies (e.g., millions of unique words), which slowed training and required vast memory. Subword tokenization (like BPE) reduced vocabulary size by breaking words into reusable pieces (e.g., “run” + “s”), making it feasible to process diverse texts efficiently. This scalability was crucial for the Transformer’s parallel processing, as introduced in the 2017 paper.
- Supporting the Transformer’s Architecture:
- The Transformer relies on fixed-size vocabularies and vector embeddings to encode tokens. Tokenization ensures raw text is converted into a format compatible with self-attention, where each token’s vector is processed simultaneously. In our example, tokenizing “The cat runs!” into [1, 2, 3, 4, 5] allowed the Transformer to apply matrix operations efficiently.
- Powering GPT’s Generative Capabilities:
- GPT, built on the Transformer’s decoder, uses subword tokenization (specifically BPE in later versions like GPT-2 and GPT-3) to handle diverse inputs and generate coherent text. By tokenizing text into subword units, GPT can manage rare words, misspellings, and even non-English languages. For instance, it can generate “running” by combining “run” and “##ing,” leveraging the same tokenization strategy.
- Pre-training and Generalization:
- GPT’s pre-training on massive datasets (e.g., web text) relies on tokenization to create a consistent vocabulary across diverse sources. This allows GPT to learn general language patterns, which are fine-tuned for tasks like answering questions or writing stories. Tokenization’s ability to handle varied text ensures GPT’s versatility.
- From Translation to Open-Ended Generation:
- The Transformer was designed for tasks like translation, where tokenization splits input and output sentences into tokens. GPT extended this to open-ended generation, using tokenization to process prompts and generate responses token by token. In our example, GPT might start with “The cat” (tokens [1, 2]), predict “run” (ID 3), then “s” (ID 4), and “!” (ID 5), decoding them into a complete sentence.
Why Tokenization Matters
Tokenization is the unsung hero of NLP, transforming messy human language into structured tokens that models like the Transformer and GPT can process. By breaking text into subword units, it addresses the limitations of early word-based approaches, enabling scalability, flexibility, and robustness. The “Attention Is All You Need” paper leveraged tokenization to feed clean inputs into the Transformer’s self-attention mechanism, while GPT built on this to generate human-like text. From encoding tokens into vectors to decoding outputs back into words, tokenization is the glue that holds the NLP pipeline together.
For a deeper dive, explore the original Transformer paper here or check out resources on BPE and GPT’s tokenization strategies. Tokenization may seem like a small step, but it’s a giant leap toward making AI as conversational as we are.